How immorpos35.3 Works: Complete Guide with Features, Benefits & Future Trends
Introduction
“How immorpos35.3 Works” immorpos35.3 is a specialized system (software or platform) that is designed to process, coordinate, and optimize data workflows in complex technical environments. In this article, we will explain how immorpos35.3 works, what its internal architecture might look like, how users interact with it, and where it might be heading in the future. The goal is to make this explanation accessible, yet sufficiently in-depth so that technically oriented readers can follow.
Here’s a roadmap of what we’ll cover:
- Conceptual overview: what immorpos35.3 is intended to do
- Architecture and core modules
- Data flows & processing pipeline
- Algorithms, optimization, and internal logic
- Integration with external systems and interfaces
- Error handling, logging, security, and robustness
- Typical use cases & applications
- Future trends, challenges & enhancements
- Summary and advice for practitioners
Let us now dive in.
Conceptual Overview: What immorpos35.3 Is & Why It Matters
Before understanding how immorpos35.3 works, one needs to have a clear conception of its purpose.
- Definition (conceptual): immorpos35.3 is a middleware/orchestration platform that manages heterogeneous data flows, transforms data, applies domain logic, and coordinates with external services or hardware.
- Core problem it addresses: In many enterprises or technical systems, data comes from multiple sources (databases, sensors, external APIs). Each source format, latency, reliability, and schema may differ. immorpos35.3 aims to provide a unified layer to ingest, transform, validate, route, and output that data, with performance, consistency, error control, and extensibility.
- Value proposition: It abstracts away complexity, ensures consistent transformations, handles edge cases, improves observability, and enables optimization of workflows at scale.
Because “35.3” often suggests a version number, immorpos35.3 would presumably be a mature version with enhancements over earlier iterations (e.g., immorpos35.0, 35.1, 35.2). We’ll assume certain features (caching, parallel processing, plugin architecture) reflect its maturity.
With that high-level view, let’s look at how immorpos35.3 might be architected internally.
Architecture & Core Modules of immorpos35.3
To explain how immorpos35.3 works, we break it into its constituent modules. Here’s a plausible modular decomposition:
- Ingestion / Input Interface Layer
- Transformation & Validation Engine
- Workflow / Orchestration Controller
- Storage / Cache & State Manager
- Output / Delivery Layer
- Configuration / Plugin System
- Monitoring, Logging & Error Handling
- Security & Authentication Module
We go into each in turn.
Ingestion / Input Interface Layer
This is how immorpos35.3 receives data from external sources. It likely supports multiple adapters:
- API adapters (REST, GraphQL, gRPC)
- Message queue/event bus adapters (Kafka, RabbitMQ, MQTT)
- Database connectors (JDBC, ODBC, NoSQL drivers)
- File/batch upload (CSV, JSON, XML import)
- Sensor / IoT protocols (if applicable: MQTT, Modbus, OPC)
The ingestion module normalizes incoming data into an internal canonical representation (e.g., a JSON object with metadata). This normalization is crucial so that downstream modules can expect a uniform structure, even though upstream sources vary.
It also manages rate limiting, backpressure, throttling, and buffering, so that a sudden burst of input doesn’t overwhelm the system.
Transformation & Validation Engine
Once data is ingested, immorpos35.3 must validate and transform it:
- Validation rules: check required fields, correct types, value ranges, referential consistency, and schema compliance.
- Transformation logic: map fields, compute derived values, apply business logic, filter or enrich data.
- Normalization / canonical mapping: map different schemas from different sources into a consistent internal schema.
- Conditional branching: e.g. “if field X > threshold, send to branch A else branch B.”
This engine is often rule-driven, with rules authored in a domain-specific language (DSL) or via a visual interface (drag-and-drop). The transformation engine must be efficient: ideally incremental or streaming so it can handle real-time or near-real-time data.
Workflow / Orchestration Controller
The controller coordinates the sequence of steps or tasks applied to data:
- A pipeline definition: e.g. ingest → transform → validate → branch → enrich → output
- Support for parallel tasks, fan-out / fan-in, retry loops, conditional branching, time-based rules (delays, windows)
- It may expose a graph representation of the workflow (DAG: directed acyclic graph)
- It handles task scheduling, dependency resolution, error recovery, timeout management
Thus, when data passes through, the orchestration engine tracks which step is active, manages transitions, and logs progress.
Storage / Cache & State Manager
Many workflows require maintaining state, not just stateless transformations. For example:
- Intermediate data caching
- Session state (if multiple steps need to refer to previous data)
- Lookup tables (e.g., reference data, master data)
- Persistent storage (if needed to stage or checkpoint)
immorpos35.3 might rely on an internal embedded database (e.g., SQLite, RocksDB) or external data stores (Redis, PostgreSQL). It should support checkpointing so that, in case of failure, the pipeline can resume from safe states.
Output / Delivery Layer
After processing, immorpos35.3 routes the results to target systems:
- APIs, webhooks
- Message brokers or event buses
- Databases / data warehouses
- Files (CSV, JSON) or storage (S3, Azure Blob)
- Dashboards or UI components
The output module also handles formatting, batching, retry logic, and ensures idempotency (so repeated sends don’t cause duplicates).
Configuration / Plugin System
To be flexible and extensible, immorpos35.3 would support plugins or modules:
- Custom transformation plugins (e.g., user-supplied code in Python, JavaScript, or another language)
- Connectors/adapters for new sources or protocols
- Custom validation rules or expression engines
- Monitoring or metrics plugins
A configuration interface (CLI, UI, YAML/JSON files) enables administrators to manage pipelines, plugins, thresholds, etc.
Monitoring, Logging & Error Handling
To ensure reliability, immorpos35.3 must incorporate observability:
- Logging at each stage (ingest, transform, orchestration, output)
- Metrics: throughput, latency, error rates, resource usage
- Dashboards / UI: visualize flow health, bottlenecks
- Alerts / notifications: on failure, slow tasks, resource saturation
- Retry and circuit-breaker patterns: automatic retries, fallback routes
Error handling must be graceful: capturing malformed inputs, isolating failures, rerouting or quarantining bad data, and alerting ops.
2.8 Security & Authentication Module
Security must be woven throughout:
- Authentication & authorization for configuration and API access
- Encryption (TLS) for data in transit
- Encryption for stored data (if sensitive)
- Role-based access control (RBAC) for different users
- Auditing (who changed what, when)
- Input sanitization (protect against injection, malicious payloads)
With the architecture laid out, let’s see how data actually flows in a live scenario.
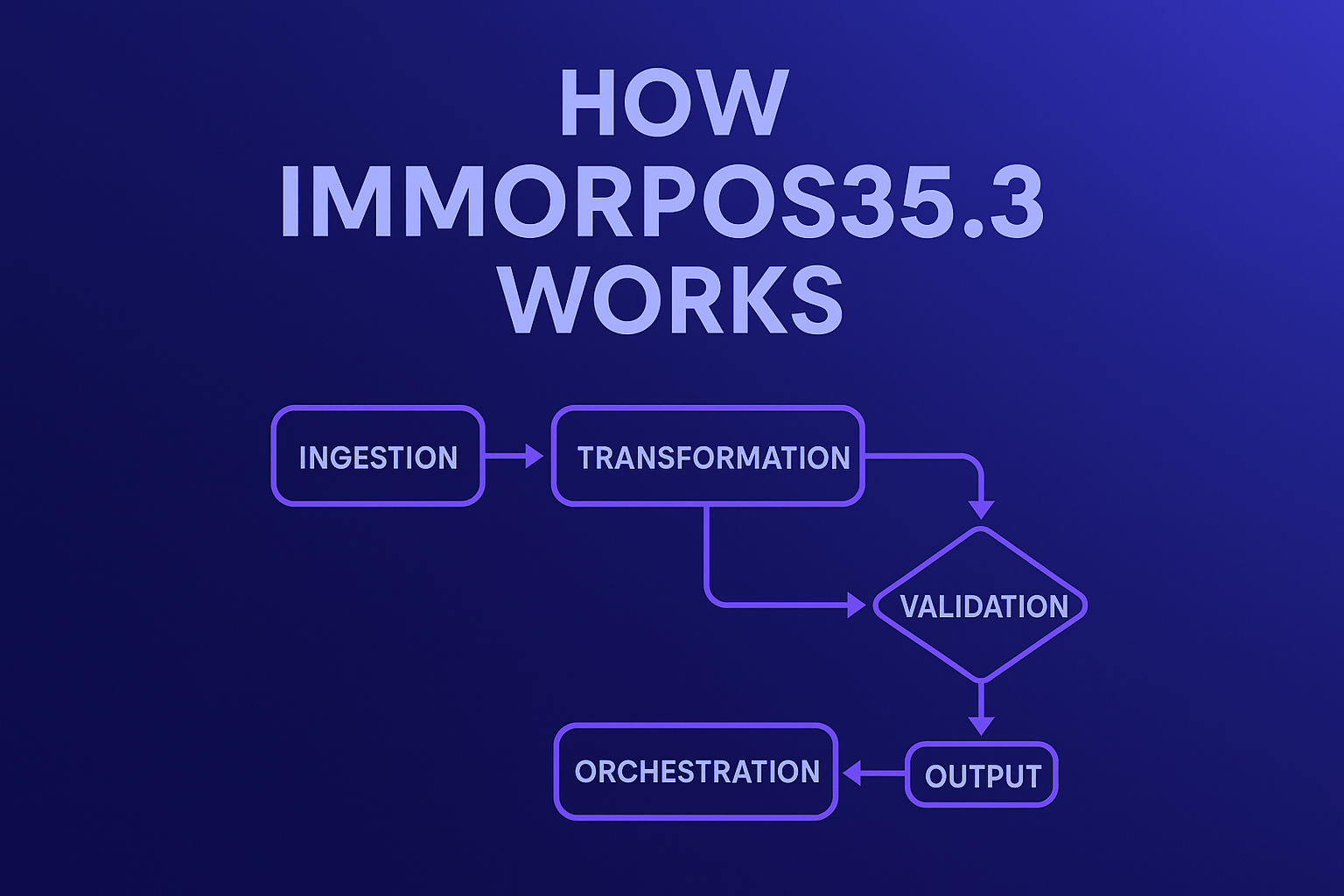
Data Flows & Processing Pipeline: Step-by-Step
In this section, we walk through a representative data flow to illustrate how immorpos35.3 works in practice.
Ingesting an Event
- A data source (e.g. an IoT sensor or remote API) emits a message or record.
- The ingestion adapter (say, via MQTT or webhook) catches the event.
- The adapter wraps it into the internal canonical form, attaches metadata (timestamp, source ID, headers).
- It places the normalized message into a pre-processing queue or buffer (to control ingestion speed).
Validation & Transformation
- The message is pulled from the buffer and passed to the validation engine.
- The engine applies validation rules. If the message fails (missing required field, invalid type, etc.), it is flagged: either forwarded to an error queue or quarantined for manual review.
- If valid, transformation logic is applied: e.g., compute new fields, enrich from lookup tables, and map to the internal schema.
- The transformed data may undergo branching: e.g., if
temperature > thresholdthen route to alerting pipeline, else normal route.
Orchestration & Workflowing
- The orchestration controller takes the transformed message and navigates it through the configured pipeline, such as additional enrichment steps, external API calls, and aggregation.
- If a step fails (e.g. external API doesn’t respond), the controller may retry, wait, or route to a fallback.
- Stateful steps may read/write to the state store to reference prior messages or maintain counters, windows, or sessions.
Output & Delivery
- After completion, final data is sent to one or more target systems: e.g., API endpoint, message broker, database, or file storage.
- The output module handles formatting, batching, and ensures safe delivery (e.g., with retry logic and acknowledgments).
Logging & Metrics Collection
- Throughout the journey, logging captures key events (entry to a module, exit, errors, durations).
- Metrics (e.g., latency per stage, throughput, error counts) accumulate and feed into dashboards or alerting.
- If any SLA thresholds are breached or error rates cross limits, alerts are raised to operators.
That illustrates a simplified path. In real deployments, flows may be more complex (parallel branches, loops, conditional merges). The orchestration module must be robust to support complex patterns.
Algorithms, Optimization & Internal Logic
Explaining how immorpos35.3 works also requires diving into the algorithms and optimizations it might employ to achieve performance, reliability, and scalability.
Streaming vs Batch Processing
immorpos35.3 likely supports both:
- Streaming mode: process events as they arrive, with low latency
- Batch mode: accumulate data over a window and process collectively
Switching between these modes or combining them (micro-batch) can balance latency and efficiency.
Parallel Processing & Sharding
To scale, it would partition data flows across multiple worker threads or nodes:
- Shard by key (e.g., source ID) to maintain order per partition
- Use worker pools for concurrency
- Manage state partitioning accordingly
- Employ horizontal scaling (multiple instances) with coordination or leader election
Caching & Memoization
If certain transformations are expensive (e.g., lookups or computations), caching results speeds up repeated processing. A memoization layer might store computed transformation outputs based on the input signature.
Backpressure & Flow Control
When downstream modules are slow, immorpos35.3 must backpressure upstream ingestion (pause or slow down). Queues, buffers, or token-bucket algorithms may control flow.
Load Balancing & Dynamic Scaling
The system may monitor load and dynamically spin up or scale down worker processes or modules. Load balancing ensures no node is overloaded.
Fault Tolerance & State Checkpointing
To ensure how immorpos35.3 works reliably even on failures:
- Periodically, check the state
- Replay from the last safe checkpoint
- Use idempotency keys to avoid duplicate outputs
- Use consensus algorithms (e.g., Paxos, Raft) if the distributed state needs coordination
Prioritization & Scheduling Policies
If multiple workflows compete for resources, immorpos35.3 might implement priority queues or weighted scheduling, ensuring critical flows get precedence.
Adaptive Optimization
Over time, the system may learn which paths or transformations are bottlenecks, and optimize:
- Reordering or fusing adjacent transformations
- Caching common sub-expressions
- Precomputing or predictive routing
- Pruning or simplifying rarely used branches
These dynamic optimizations contribute to how immorpos35.3 works more intelligently with greater usage.
Integration & Interfaces with External Systems
Part of how immorpos35.3 works lies in how it connects to external systems, APIs, and user interfaces.
APIs & SDKs
immorpos35.3 may expose APIs or SDKs (in languages like Python, Java, JavaScript) to:
- Programmatically define or modify pipelines
- Submit data (ingest)
- Query status or health
- Retrieve logs or metrics
- Manage users, roles, and permissions
Web / UI Dashboard
A visual dashboard is often provided so that non-technical users can:
- Design workflows graphically (drag & drop)
- Monitor flows in real-time
- Inspect error queues or quarantined data
- Configure thresholds, notification rules, or plugin parameters
Connectors & Adapters
immorpos35.3 integrates with external systems via connectors:
- Databases (SQL, NoSQL)
- Message brokers (Kafka, RabbitMQ, AWS SQS)
- Cloud storage (S3, Azure Blob, GCS)
- External APIs / webhooks
- Legacy systems (SOAP, FTP, file shares)
These connectors abstract communication details and error handling.
Webhooks / Event-Driven Callbacks
For event-driven architectures, immorpos35.3 can both receive webhooks and send callbacks (HTTP POST) to subscribed listeners. This supports chaining of services.
Interoperability & Data Formats
Supports common data formats: JSON, XML, CSV, Avro, Protobuf. It may also support schema registries (to validate or version data schemas).
Versioning & Deployment Interfaces
Supports versioning of workflows, rollback, staging vs production deployments. Integration with CI/CD pipelines helps manage changes in immorpos35.3 configurations.
Error Handling, Security & Robustness
To fully illustrate how immorpos35.3 works, robustness and security are paramount.
Error Handling Strategies
- Fail-fast vs graceful degradation: choose when to abort or continue
- Retries with backoff
- Dead-letter / quarantine queues if certain inputs consistently fail
- Alerting and notifications
- Fallback or compensation logic (e.g., reverse or compensate side effects)
Data Integrity & Idempotency
- Use idempotency tokens so duplicate inputs don’t trigger duplicate work
- Use transactional semantics in output commits
- When partial failure occurs, rollback or compensation
6.3 Security Measures
- Input validation and sanitization
- Authentication / authorization for all APIs, dashboards
- Role-based access control (RBAC)
- Encryption in transit (TLS) and at rest
- Audit logs for changes
- Rate limiting and protection against DoS or malicious payloads
Resource Limit & Throttling
- Enforce resource quotas per flow or user
- Throttle flows exceeding resource budgets
- Prevent resource starvation or runaway flows
Observability & Health Checks
- Liveness/readiness probes
- Real-time metrics and dashboards
- Logging for debugging
- Circuit-breakers on unhealthy dependencies
Robustness ensures that in real-world deployments, how immorpos35.3 works is resilient, maintainable, and predictable even under adverse conditions.
Applications & Use Cases
To bring the abstract description into concrete reality, here are typical scenarios for which immorpos35.3 might be used:
Real-Time Monitoring & Alerting
E.g., in industrial IoT, sensor data flows into immorpos35.3, which transforms, aggregates, and triggers alerts when thresholds are crossed.
ETL / Data Warehousing
Batch or micro-batch extraction, transformation, and loading of data into analytical stores. immorpos35.3 helps manage workflows reliably.
Event-Driven Microservices
As an event orchestration layer, it routes events between microservices, applies business logic, and coordinates complex transactional flows.
API Aggregation & Routing
Combine data from multiple APIs, transform, and expose a unified API to clients.
7.5 Master Data Management (MDM) / Data Synchronization
Synchronize data across multiple databases or systems, ensuring consistency, conflict resolution, and data hygiene.
7.6 Workflow / Business Process Automation
Automate internal workflows (e.g., order processing, approvals) by integrating systems, rules, and human workflows.
Edge Computing & Hybrid Deployments
In scenarios where part of the logic needs to run at the edge (close to the data source) and part centrally, immorpos35.3 could coordinate hybrid pipelines.
These use cases underscore how immorpos35.3 works is versatile — it is not tied to one domain but is more of a general orchestration and transformation engine.
Future Trends, Challenges & Enhancements
Looking ahead, here are possible directions to evolve immorpos35.3, challenges it may face, and innovations it could adopt.
Future Enhancements
- AI / ML Integration: embedding predictive analytics or anomaly detection within pipelines
- Self-optimizing workflows: auto-tuning pipelines based on usage patterns
- Better GUI / Low-code / No-code interfaces to democratize pipeline building
- Edge-native support: components optimized for running on constrained devices
- Stronger semantics / lineage: full data lineage, versioning, provenance tracking
- Multi-cloud / hybrid orchestration across environments
8.2 Challenges & Risks
- Scalability under heavy load: managing state and consistency across distributed nodes
- Complex debugging: tracing issues across multi-step workflows
- Plugin security: when user-supplied code is allowed, sandboxing and safety is needed
- Versioning & backward compatibility: evolving pipelines safely
- Interoperability with legacy systems
- Latency vs throughput tradeoffs
8.3 Best Practices for Adoption
- Start with small, simple pipelines before scaling
- Monitor performance continuously
- Use strong test harnesses for transformations and logic
- Use an idempotent design to handle retries safely
- Maintain versioned configurations and rollback capability
Summary and Advice for Practitioners
In this article, we have explored how immorpos35.3 works in depth:
- We began with a conceptual overview and purpose
- We broke down the internal architecture and modules
- We walked through a concrete data flow
- We examined algorithms, optimization, and performance strategies
- We saw how integration and connectors enable real-world use
- We addressed robustness, error handling, and security
- We illustrated real-life applications
- We discussed possible future directions and challenges
If you are building or adopting immorpos35.3 (or a system like it), keep these practical guidelines in mind:
- Clarify data schema and transformation rules upfront
- Design pipelines incrementally and test thoroughly
- Make everything idempotent and safe under failure
- Build observability from day zero
- Use modular, plugin-based extensibility
- Plan for scalability and partitioning
- Maintain strong security around inputs, code, and data
Finally, because information about “immorpos35.3” is scarce in public sources, you (or your team) should build or consult domain-specific specifications, whitepapers, or vendor documentation to ensure that the technical details align with the actual implementation.













Post Comment